Thrift学习笔记
是什么
Thrift是一个跨语言的RPC框架,它可以通过Thrift的IDL(接口定义语言)来描述接口函数及数据类型,编译后可以自动生成服务端的框架代码。
RPC框架可以分为服务治理和跨语言调用两大类型。前者一般和语言耦合度高,且提供了丰富的功能(负载均衡,服务注册与发现等),比如Java的Dubbo框架。而后者主要解决不同语言的服务间的调用问题,没有太多花哨的功能,比如gRPC,Thrift。
优缺点
优点是可以跨语言使用,性能优秀,自动生成服务端代码,使用起来简单方便。
缺点是没有动态特性。
原理
Thrift是一种C/S的架构体系.在最上层是用户自行实现的业务逻辑代码。下层是由Thrift编译器自动生成的代码,主要用于结构化数据的解析,发送和接收。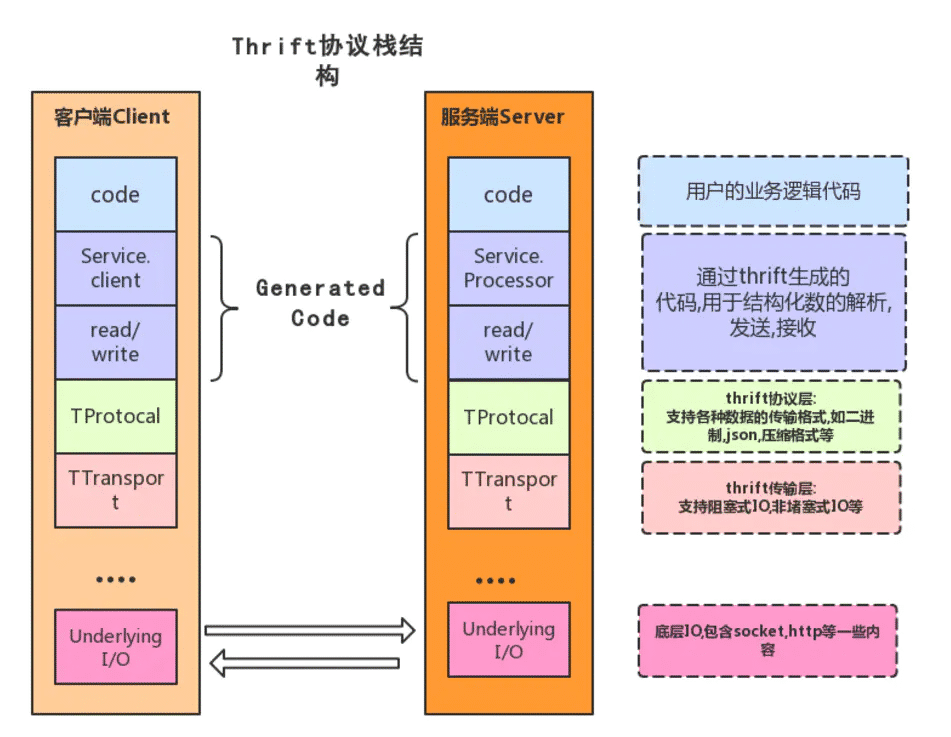
Transport:
为从网络进行读写提供了简单的抽象。负责以字节流方式接收和发送消息体,不关注是什么数据类型。底层IO负责实际的数据传输,包括socket、文件和压缩数据流等。它解耦了上层部分(如序列化)与数据的传输。
Protocol:
TProtocol是用于数据类型解析的,即序列化和反序列化,将结构化数据转化为字节流给TTransport进行传输。
Processor:
从输入流中读入数据,然后委托给处理代码进行处理(自己编写),最后写到输出流中。输入、输出流由下层的Protocal对象提供,接口非常简单:
1 | interface TProcessor { |
Server:
整合了上面所有的功能:
- Create a transport
- Create input/output protocols for the transport
- Create a processor based on the input/output protocols
- Wait for incoming connections and hand them off to the processor
实例
我们使用Thrift实现一个匹配系统,客户端调用远程服务器将用户两两间进行匹配,比如玩各种1V1游戏时,将段位相似的玩家匹配到一起。客户端使用Python,服务端使用Java。
源码在 https://github.com/xiaoxiaokun/ThriftDemo。
定义服务器接口
使用thrift定义的类型写一个thrift文件,再使用 thrift -r --gen <language> <thrift file> 自动生成客户端和服务端代码
1 | namespace java match |
使用命令生成的源码主要有两个文件,一个文件封装thrift中定义的接口方法,一个文件封装定义的类型。我们只需要在服务端实现该接口,在客户端调用该接口即可。
客户端
使用Python编写,用上述命令生成Python源码,主要得到 ttype.py 和 Math.py 两个文件。我们新建一个client.py文件来编写客户端的操作,先获取一个连接服务器的客户端对象,该对象中有在Thrift中写的接口方法,再直接调用即可:
1 | from pydoc import cli |
服务端
用Java编写,生成源码后得到 Match.java 和 Player.java 文件,和生成的Python源码类似。
Match主要提供了Iface的接口,我们只要实现其中的add和remove方法即可,其余的创建Transport、创建Protocol、创建Server只需要调用Thrift提供的现成的实现类就好,而且Thrift对每一层的接口都提供了多种实现,用户可以根据需要选择合适的实现类,比如Server层提供了单线程和多线程实现,处理器也提供了同步和异步的实现。
创建一个 MatchServerHandle 类来实现接口中的方法:
1 | public class MatchServerHandle implements Match.Iface { |
创建一个服务端的启动类,负责监听客户端请求,并创建添加、移除玩家的任务:
1 | public class MatchServer { |
还需要一个类负责处理任务,进行玩家间的匹配:
1 | public class MatchPool { |
这样就基本完成了,同时启动客户端和远处的服务端,在Python客户端中输入,远程的Java服务进行处理后返回响应。
